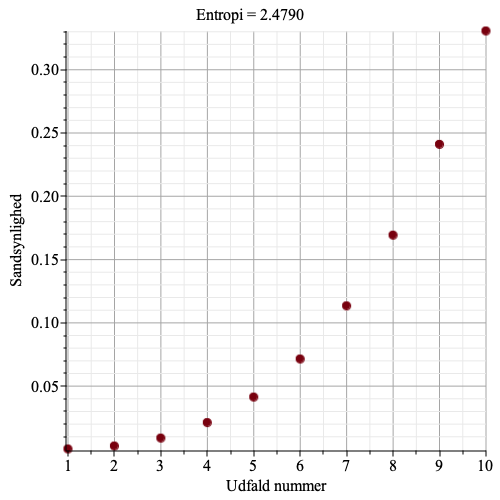
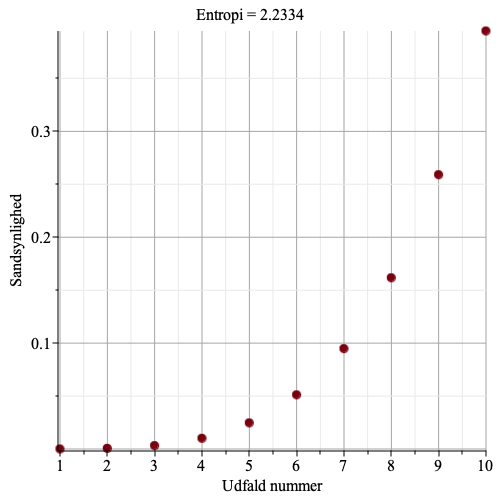
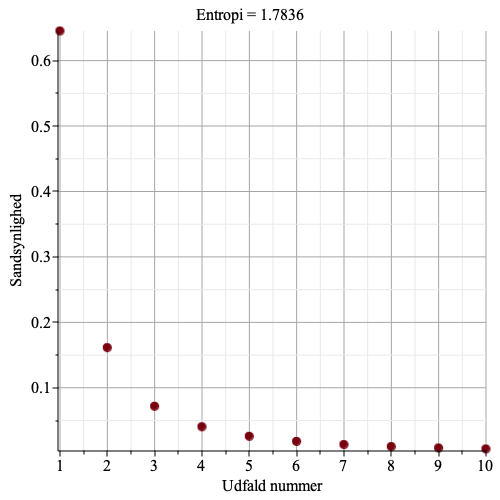
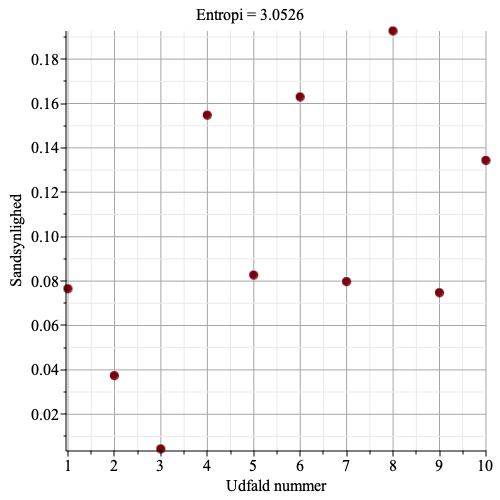
Nu bliver det spændende.
Vi har set på Theil-indekset \(T\) for en mængde individer, hvor indeks i summerer over alle n individer. Her er \(x_i\) indkomsten for person nummer i, og \(\mu\) er den gennemsnitlige indkomst.
\(T = \frac{1}{n} \cdot \sum_{i=1}^{n} \frac{x_i}{\mu} \cdot \log_2(\frac{x_i}{\mu})\)
Vi har set på Theil-indekset \(T_G\) for grupper af individer, hvor indeks j summerer over alle m grupper. I udledningen antog vi at alle individer i samme gruppe har samme indkomst \(x_j\), med \(n_j\) som antallet af medlemmer i gruppe j, og med \(\mu\) er den gennemsnitlige indkomst udregnet ud fra samtlige n individer.
\(
T_G = \sum_{j=1}^m \frac{n_j}{n} \cdot \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
\)
Formlen for Theil-indekset for grupper svarer til Theil-indekset for individer, dog er bidraget fra hver gruppe ganget med \(\frac{n_j}{n}\) som er den andel individerne i gruppe j udgør af det totale antal individer.
Vi vil nu se på det der kaldes for dekomposition af Theil-indekset.
Antag at vi har n individer. Hver af de n individer hører til i én gruppe. Vi kan beregne Theil-indekset for alle individer. Det giver et mål for den samlede ulighed. Det viser sig, at Theil-indekset for alle individer kan deles i to del:
Del 1 : Theil-indekset for grupperne, der sammenligner ulighed mellem grupperne.
Del 2 : Theil-indekset for individer i samme gruppe, der sammenligner ulighed indenfor grupperne.
Har vi f.eks. data over alle individer i Danmark, deres indkomst, og i hvilken kommune de hører til, så kan vi beregne Theil-indekset for alle danskere. Dette Theil-indeks kan opdeles i to dele, nemlig et bidrag fra ulighederne kommunerne imellem, og et bidrag fra ulighederne indefor de enkelte kommuner. Og vigtigt; vi kan faktisk beregne de forskellige bidrag. Dermed kan vi ikke bare sammenligne kommune med kommune, men også indkomstfordelingen indenfor de de enkelte kommuner.
Det viste sig at være lidt vanskeligt at få det, med dekomposition af Theil-indekset, ‘i kassen’, for det er ikke al information man finder på nettet som er lige præcis, troværdig, gennemarbejdet. Heldigvis kan man jo regne på det selv, og så sammenligne resultatet man får med de forskellige kilder. Jeg mener selv at jeg har nået frem til et korrekt udtryk for dekompositionen, og jeg er ret sikker på fortolkningen af dekompositionen.
Der indgår mange forskellige størrelser i den endelige formel, og det siger sig selv, at det ikke er lige meget hvad hver enkelt størrelse betyder. Her er en oversigt over de størrlser jeg bruger.
Der er n individer i alt. Gennemsnitsindkomsten for alle er \(\mu\).
Alle individer inddeles i m grupper:
Gruppe 1 består af \(n_1\) individer. Deres gennemsnitsindkomst er \(x_1\) Gruppe 2 består af \(n_2\) individer. Deres gennemsnitsindkomst er \(x_2\) ... Gruppe m består af \(n_m\) individer. Deres gennemsnitsindkomst er \(x_m\)
Jeg bruger indekset j til grupperne. Når j = 1 er der således tale om gruppe 1, når j = 2 er der tale om gruppe 2, o.s.v.
De forskellige individers indkomst benævnes \(x_{ji}\), hvor j er gruppens nummer, og i er individets nummer i denne gruppe. F.eks. er \(x_{53}\) indkomsten af individ nummer 3 i gruppe 5.
Desuden er \(x_j\) gennemsnitsindkomsten for alle individer i gruppe j.
Man tager så udtrykket for Theil-indekset for alle individer; det er det udtryk vi har øverst på siden. Efter en del omskrivninger (kommer senere) kan dette udtryk skrives om til følgende udtryk:
\(
T = \sum_{j=1}^m \sum_{i=1}^{n_j} \frac{x_{ji}}{n \cdot \mu} \cdot \log_2(\frac{x_{ji}}{x_j})
+
\sum_{j=1}^m \frac{n_j}{n} \cdot \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
\)
Den første sum på højre side kan skrives som
\(
\sum_{j=1}^m \frac{n_j}{n} \cdot \frac{x_j}{\mu} \cdot T_j \quad \textrm{ med } \quad
T_j = \frac{1}{n_j} \cdot \sum_{i=1}^{n_j} \frac{x_{ij}}{x_j} \cdot \log_2(\frac{x_{ji}}{x_j})
\)
hvor \(T_j\) er Theil-indekset for alle individer i grupper j .
Den sidste sum er Theil-indekset \(T_G\) for grupperne, se næstøverste formel.
Dermed ender vi med dekompositionen
\(
\sum_{j=1}^m \frac{n_i}{n} \cdot \frac{x_i}{\mu} \cdot T_j + T_G
\)
Første sum måler uligheden indenfor hver gruppe j, og vægter dem efter antal individer i gruppe j og gennemsnitsindkomsten i gruppe j, i forhold til det samlede antal individer og det samlede gennemsnit. Anden del er, som nævnt, ikke andet end Theil-indekset for grupperne; her måles uligheden mellem de forskellige grupper.
Pointen i dekompositionen er, at den samlede ulighed for alle individer kan skrives som én del der måler uligheden indenfor hver enkelt gruppe, og én del som måler uligheden mellem de forskellige grupper.
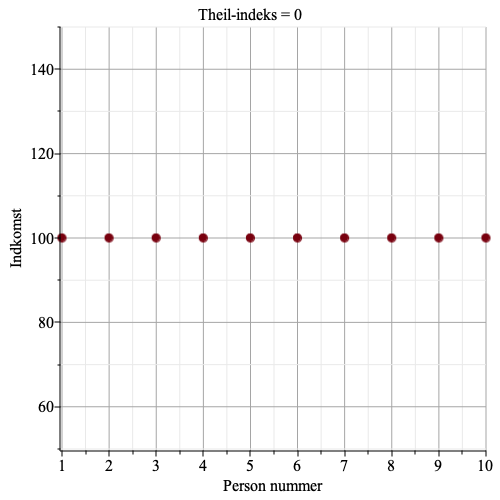
Eksempel 1. Hvis alle indkomster er ens, så er der ingen ulighed mellem grupperne, og der er ingen ulighed indenfor grupperne, så begge bidrag til Theil-indekset er nul, og hele Theil-indekset er nul.
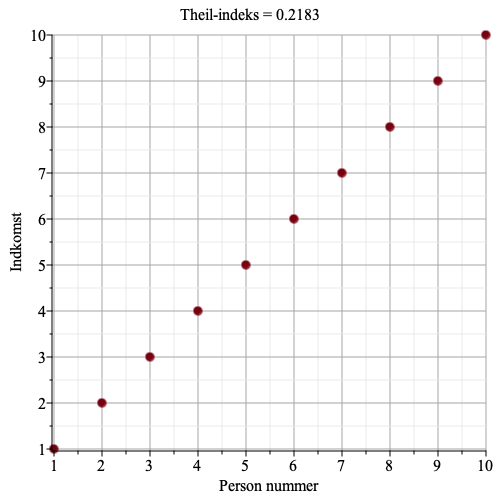
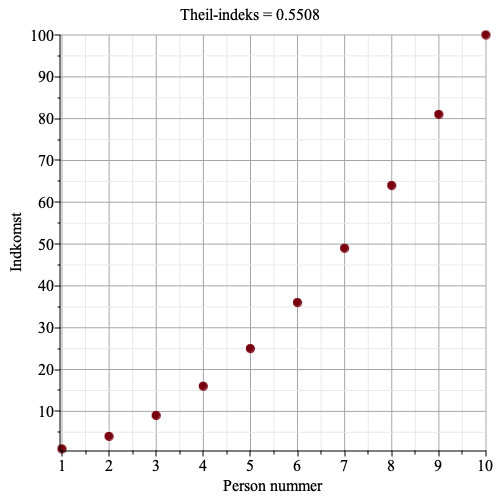
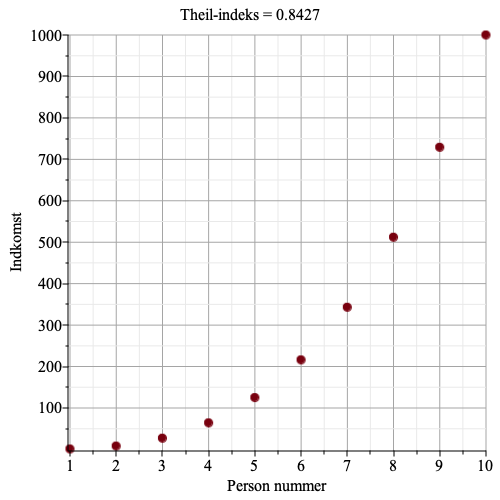
Eksempel 2. Er gennemsnitsindkomsten i alle grupper nogenlunde ens, men er der er forholdsvis stor spredning indefor de enkelte grupper, så vil bidraget til det samlede Theil-indeks fra gruppeuligheden være lille, og bidraget fra uligheden indenfor de enkelte grupper være forholdsmæssig stor.
Eksempel 3. Simulation med Maple. 10 grupper, 100 personer i hver gruppe. Gennemsnitsindkomst i gruppe j er normalfordelt med middelværdi 5000+1000 j og spredning 1000.
Tabellen viser bidragene til det samlede Theil-indeks fra ulighed indenfor de enkelte grupper og fra ulighed grupperne imellem. Det samlede Theil-indeks blev 0.06077.
| Internt i gruppe | Grupperne imellem | |
| Gruppe 01 | 0.000941 | -0.046299 |
| Gruppe 02 | 0.000894 | -0.039794 |
| Gruppe 03 | 0.000860 | -0.027383 |
| Gruppe 04 | 0.000828 | -0.016148 |
| Gruppe 05 | 0.000652 | -0.009024 |
| Gruppe 06 | 0.000591 | 0.007728 |
| Gruppe 07 | 0.000624 | 0.022502 |
| Gruppe 08 | 0.000428 | 0.036204 |
| Gruppe 09 | 0.000562 | 0.054449 |
| Gruppe 10 | 0.000497 | 0.071667 |
| Samlet | 0.006877 | 0.053900 |
Vi ser at bidragene til Theil-indekset, fra intern ulighed i grupperne, er størst for de første grupper. Det skyldes at gennemsnits-indkomsten i disse grupper er mindst, og med en fast spredning er variationen i indkomsterne større end i de sidste grupper med en større gennemsnitsindkomst, og samme spredning på indkomsten.
Bidragene til Theil-indekset fra grupperne er negative for de første grupper. Det skyldes at gennemsnits-indkomsten i disse grupper er mindre end den samlede gennemsnitsindkomst. Bemærk at bidragene fra ulighederne internt i grupperne alle er positive; det skyldes at hver af størrelserne er reelle Theil-indeks, bare beregnet for hver gruppe for sig.