Inden vi kommer dertil skal vi se på begrebet kongruens.
Kongruens, og restklasser som vi ser på i næste afsnit, spiller en stor rolle inden for talteorien, og ligger til grund for f.eks. RSA kryptering.
I princippet kan man klare definitionerne af kongruens og restklasser på et par linier, men så forsvinder forståelsen.
Det med kongruens og restklasser lyder måske svært, men det er det på ingen måde.
Formålet med de næste afsnit er at forklare begreberne på en sådan måde, at læseren ikke bare præsenteres for færdige begreber, men også får en forståelse for hvad der foregår, og, hvad der også er vigtigt, ser nogle indre billeder for sig, når snakken handler om to begreber.
Vi har før set på de hele tal. Symbolet for de hele tal er \[\mathbb{Z}\] , og det er mængden
Lad os tage de første ca. 50 hele tal og skrive dem ind i en tabel.
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
Kongruens modulo 5
En række i en tabel er tal der står ved siden af hinanden. En søjle i en tabel er tal der står lodret over hinanden.
Vi indfører nu et nyt tegn: \[\equiv\]
Tegnet \[\equiv\] læses ‘kongruent med’. Ordet ‘kongruent’ betyder noget i retningen af at være ens. Konkruente figurer er figurer der, ved at flytte dem rund, kan lægges 100% ovenpå hinanden.
Betragt tabellen herover. To tal er kongruente, hvis de hører til i samme søjle i tabellen.
F.eks. er \[17 \equiv 42\] og \[35 \equiv 0\].
Alle tal i samme søjle er kongruente med hinanden.
Det er klart at ethvert helt tal er kongruent med enten 0, 1, 2, 3 eller 4.
Når vi har tallene 0, 1, 2, 3, 4 i første række, så siger man at man ser på kongruens modulo 5.
Hvis vi vil se på kongruens modulo 7, så skal vi bare have tallene 0, 1, 2, 3, 4, 5, 6 i første række:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
Kongruens modulo 7
Når vi ser på kongruens modulo 5, så er \[10 \equiv 0\].
Når vi ser på kongruens modulo 7, så er \[10 \equiv 3\].
Hvis man både ser på kongruens modulo 5 og kongruens modulo 7,. så er det altså ikke klart om \[10 \equiv 0\] eller \[10 \equiv 3\]. Derfor skriver man f.eks.
\[10 \equiv_5 0\]
og
\[10 \equiv_7 3\]
Man kan også skrive
\[10 \equiv 0 \textrm{ (mod 5)}\]
og
\[10 \equiv 3 \textrm{ (mod 7)}\]
Jeg vil holde mig til første skrivemåde, idet den anden med (mod 5) let bliver uoverskuelig når der står (mod 5) mange gange i samme linie.
Er det klart at vi f.eks. ser på kongruens modulo 5, så skrives bare \[\equiv\] uden 5’tallet for neden.
Vi kan lægge to hele tal sammen: \[2 + 3 = 5\] Vi kan trække et helt tal fra et andet helt tal: \[7 – 4 = 3\] Vi kan gange to hele tal: \[ 2 \cdot 5 = 10 \]
Der er naturligvis andre regneoperationer end plus, minus og gange, men pointen er, at vi har en mængde af objekter, her de hele tal, og nogle regneoperationer som vi kan bruge sammen med de hele tal.
De naturlige tal
De naturlige tal er alle de positive hele tal. Man bruger symbolet \[\mathbb{N}\] for de naturlige tal:
Følgende lille simple Python-program udfører RSA-kryptering.
For at lave det så simpelt som muligt, så viser jeg kun principperne i kryptering og dekryptering, ikke bestemmelse af de forskellige konstanter der bruges til krypteringen og dekrypteringen.
Jeg har altså ‘snydt’ ved at bruge faste værdier for følgende størrelser \[p, q, \varphi(n), e, d\]. Disse værdier har jeg beregnet ved brug af Maple. Det er samme værdier som jeg bruger i dokumentet ‘RSA med Maple’.
Man kan narurligvis også få sit Python-program til selv at beregne disse værdier, men nu handler det bare om at se hvordan der krypteres og dekrypteres ved brug af Python.
Programmet er vist herunder:
#####################
# To primtal p og q #
#####################
p = 1009
q = 2003
n = p*q
##############################
# Eulers phi-funktion phi(n) #
##############################
phi=(p-1)*(q-1)
################################################################
# Tallet e primisk med phi, og tallet d så ed = 1 (mod phi(n)) #
################################################################
e = 1009037
d = 730661
#######################################################
# Indtast din klartekst i form af et tal med få cifre #
#######################################################
m = int( input('Indtast et tal med fire cifre: ') )
###########################
# Krtptering af klartekst #
###########################
enc=pow(m,e,n)
###############################
# Dekryptering af krypt-tekst #
###############################
dec=pow(enc,d,n)
#########################################################
# Udskriv klartekst, krypt-tekst og dekodet krypt-tekst #
#########################################################
print('Din meddelelse er',m,sep=' ')
print('Kryptoteksten er',enc,sep=' ')
print('Dekrypteret er',dec,sep=' ')
Hvis du nu tænker; det vil jeg da gerne prøve, så hent Python og Idle fra siden
https://www.python.org/downloads/
Du får både editoren Idle og programmeringssproget Python med i pakken, så når du har instaleret er du klar til at komme i gang.
Husk at du kun må hente programmer fra kilder du stoler på!
Vi har set på Theil-indekset \[T\] for en mængde individer, hvor indeks i summerer over alle n individer. Her er \[x_i\] indkomsten for person nummer i, og \[\mu\] er den gennemsnitlige indkomst.
Vi har set på Theil-indekset \[T_G\] for grupper af individer, hvor indeks j summerer over alle m grupper. I udledningen antog vi at alle individer i samme gruppe har samme indkomst \[x_j\], med \[n_j\] som antallet af medlemmer i gruppe j, og med \[\mu\] er den gennemsnitlige indkomst udregnet ud fra samtlige n individer.
Formlen for Theil-indekset for grupper svarer til Theil-indekset for individer, dog er bidraget fra hver gruppe ganget med \[\frac{n_j}{n}\] som er den andel individerne i gruppe j udgør af det totale antal individer.
Vi vil nu se på det der kaldes for dekomposition af Theil-indekset.
Antag at vi har n individer. Hver af de n individer hører til i én gruppe. Vi kan beregne Theil-indekset for alle individer. Det giver et mål for den samlede ulighed. Det viser sig, at Theil-indekset for alle individer kan deles i to del:
Del 1 : Theil-indekset for grupperne, der sammenligner ulighed mellem grupperne. Del 2 : Theil-indekset for individer i samme gruppe, der sammenligner ulighed indenfor grupperne.
Har vi f.eks. data over alle individer i Danmark, deres indkomst, og i hvilken kommune de hører til, så kan vi beregne Theil-indekset for alle danskere. Dette Theil-indeks kan opdeles i to dele, nemlig et bidrag fra ulighederne kommunerne imellem, og et bidrag fra ulighederne indefor de enkelte kommuner. Og vigtigt; vi kan faktisk beregne de forskellige bidrag. Dermed kan vi ikke bare sammenligne kommune med kommune, men også indkomstfordelingen indenfor de de enkelte kommuner.
Det viste sig at være lidt vanskeligt at få det, med dekomposition af Theil-indekset, ‘i kassen’, for det er ikke al information man finder på nettet som er lige præcis, troværdig, gennemarbejdet. Heldigvis kan man jo regne på det selv, og så sammenligne resultatet man får med de forskellige kilder. Jeg mener selv at jeg har nået frem til et korrekt udtryk for dekompositionen, og jeg er ret sikker på fortolkningen af dekompositionen.
Der indgår mange forskellige størrelser i den endelige formel, og det siger sig selv, at det ikke er lige meget hvad hver enkelt størrelse betyder. Her er en oversigt over de størrlser jeg bruger.
Der er n individer i alt. Gennemsnitsindkomsten for alle er \[\mu\].
Alle individer inddeles i m grupper:
Gruppe 1 består af \[n_1\] individer. Deres gennemsnitsindkomst er \[x_1\]
Gruppe 2 består af \[n_2\] individer. Deres gennemsnitsindkomst er \[x_2\]
...
Gruppe m består af \[n_m\] individer. Deres gennemsnitsindkomst er \[x_m\]
Jeg bruger indekset j til grupperne. Når j = 1 er der således tale om gruppe 1, når j = 2 er der tale om gruppe 2, o.s.v.
De forskellige individers indkomst benævnes \[x_{ji}\], hvor j er gruppens nummer, og i er individets nummer i denne gruppe. F.eks. er \[x_{53}\] indkomsten af individ nummer 3 i gruppe 5.
Desuden er \[x_j\] gennemsnitsindkomsten for alle individer i gruppe j.
Man tager så udtrykket for Theil-indekset for alle individer; det er det udtryk vi har øverst på siden. Efter en del omskrivninger (kommer senere) kan dette udtryk skrives om til følgende udtryk:
Første sum måler uligheden indenfor hver gruppe j, og vægter dem efter antal individer i gruppe j og gennemsnitsindkomsten i gruppe j, i forhold til det samlede antal individer og det samlede gennemsnit. Anden del er, som nævnt, ikke andet end Theil-indekset for grupperne; her måles uligheden mellem de forskellige grupper.
Pointen i dekompositionen er, at den samlede ulighed for alle individer kan skrives som én del der måler uligheden indenfor hver enkelt gruppe, og én del som måler uligheden mellem de forskellige grupper.
Eksempel 1. Hvis alle indkomster er ens, så er der ingen ulighed mellem grupperne, og der er ingen ulighed indenfor grupperne, så begge bidrag til Theil-indekset er nul, og hele Theil-indekset er nul.
Eksempel 2. Er gennemsnitsindkomsten i alle grupper nogenlunde ens, men er der er forholdsvis stor spredning indefor de enkelte grupper, så vil bidraget til det samlede Theil-indeks fra gruppeuligheden være lille, og bidraget fra uligheden indenfor de enkelte grupper være forholdsmæssig stor.
Eksempel 3. Simulation med Maple. 10 grupper, 100 personer i hver gruppe. Gennemsnitsindkomst i gruppe j er normalfordelt med middelværdi 5000+1000 j og spredning 1000.
Tabellen viser bidragene til det samlede Theil-indeks fra ulighed indenfor de enkelte grupper og fra ulighed grupperne imellem. Det samlede Theil-indeks blev 0.06077.
Internt i gruppe
Grupperne imellem
Gruppe 01
0.000941
-0.046299
Gruppe 02
0.000894
-0.039794
Gruppe 03
0.000860
-0.027383
Gruppe 04
0.000828
-0.016148
Gruppe 05
0.000652
-0.009024
Gruppe 06
0.000591
0.007728
Gruppe 07
0.000624
0.022502
Gruppe 08
0.000428
0.036204
Gruppe 09
0.000562
0.054449
Gruppe 10
0.000497
0.071667
Samlet
0.006877
0.053900
Det samlede Theil-indeks på 0.061 er lig summen af de to bidrag: 0.06077 = 0.006877+0.053900
Vi ser at bidragene til Theil-indekset, fra intern ulighed i grupperne, er størst for de første grupper. Det skyldes at gennemsnits-indkomsten i disse grupper er mindst, og med en fast spredning er variationen i indkomsterne større end i de sidste grupper med en større gennemsnitsindkomst, og samme spredning på indkomsten.
Bidragene til Theil-indekset fra grupperne er negative for de første grupper. Det skyldes at gennemsnits-indkomsten i disse grupper er mindre end den samlede gennemsnitsindkomst. Bemærk at bidragene fra ulighederne internt i grupperne alle er positive; det skyldes at hver af størrelserne er reelle Theil-indeks, bare beregnet for hver gruppe for sig.
Vi vil nu udlede en formel for Theil-indekset for grupper.
Vi betynder med Theil-indekset for ‘individer’:
\[
T = \frac{1}{n} \sum_{i=1}^{n} \frac{x_i}{\mu} \cdot \log_2(\frac{x_i}{\mu})
\]
Vi har N personer, men nu er de samlet i m grupper. Alle individer i samme gruppe har samme indkomst \[x_j\]. Antallet af personer i gruppe j kalder vi \[n_j\]. Vi bruger bogstavet j som fodtegn for at tydeliggøre hvilken gruppe vi ser på.
Gruppe 1. j = 1. Indkomst for hvert individ i gruppe 1 er \[x_1\].
Gruppe 2. j = 2. Indkomst for hvert individ i gruppe 2 er \[x_2\].
...
Gruppe m. j = m. Indkomst for hvert individ i gruppe m er \[x_m\].
Den gennemsnitlige indkomst for alle de N personer kalder vi \[\mu\].
Summen i formlen for Theil-indekset er en sum over alle personernes indkomst. Vi kan opdele summen så vi først summerer over alle personer i gruppe 1, så summerer over alle personer i gruppe 2, o.s.v. Dermed får vi:
\[
T = \frac{1}{N} \sum_{j=1}^m
\sum_{i=1}^{n_j} \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
\]
I den inderste sum \[\sum_{i=1}^{n_j} \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})\] summerer vi over alle individer i samme gruppe, og deres personlige indkomst er ens. Vi får derfor \[n_j\] led der er ens, og den inderste sum giver så
Når vi skal sammenligne indkomsterne mellem grupperne, så beregner vi Theil-indekset ved brug af formlen herover. I formlen er \[n_j\] antallet af personer i gruppe j, \[x_j\] er den individuelle indkomst i grupper j, \[\mu\] er den gennemsnitlige indkomst for alle personer, og n er antallet af personer i alt i alle grupper.
Bemærk at \[n_j \cdot x_j\] er den totale indkomst i gruppe j, og \[N \cdot \mu\] er den totale indkomst i befolkningen.
Man kan diskutere det fornuftige i at antage at alle personer i samme gruppe har samme indkomst. Det kan jo være at man har udvalgt sine grupper udfra indkomst-nivaeu, og så er det naturligvis en fornuftig antalelse. Andre gange er det ikke en fornuftig antagelse, og man kan så undersøge/overveje hvilken betydning det så får. Se også ‘dekomposition af Theil-indekset’ hvor man både sammeligner individer og grupper, og finder ud af hvor meget variation i individuelle indkomster betyder for det samlede Theil-indeks, og hvor meget gruppe-variation i indkomster betyder for det samlede Theil-index.
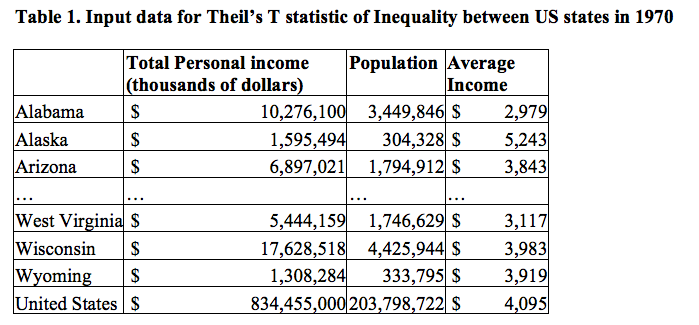
Lad os som eksempel se på data fra nogle amerikanske stater:
Vi vil beregne Alabamas bidrag til Theil-indekset:
Alabamas bidrag til Theil-indekset bliver negativt da gennemsnitsindkomsten i Alabama ligger under gennemsnitsindkomsten i USA. Alaskas bidrag til Theil-indekset beregnes på samme måde, og man får 0.00068.
For at beregne Theil-indekset for USA skal vi beregne hver af staternes bidrag til Theil-indekset, og så addere dem.
Den ideelle entropi \[H(F)\] for et forsøg \[F\] kan beregnes ved brug af formlen
\[H(F) = -\sum_{i=1}^n p_i \cdot \log_2(p_i) \]
Bemærk at logaritmen er to-tals logaritmen. Sandsynlighederne \[p_i\] er sandsynlighederne for de forskellige udfald.
Formen kan udledes ved bl.a. at se lidt nærmere på optimale spørgsstrategier, men det springer vi over her. Der henvises til Flemming Topsøes bog ‘Informationsteori’, Gyldendal 1973 hvorfra inspiration til gennemgangen af entropien er fundet.
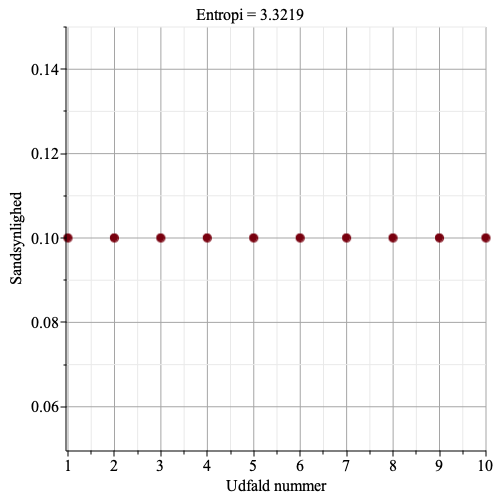
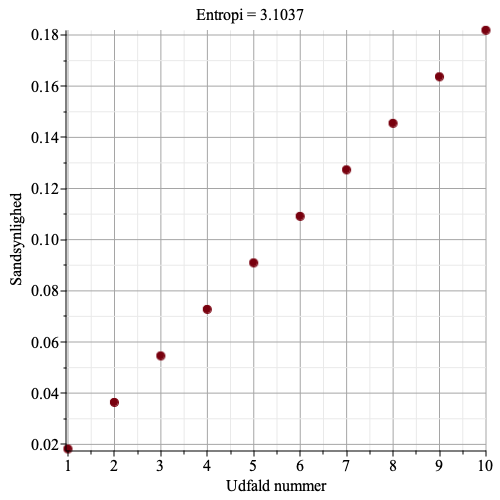
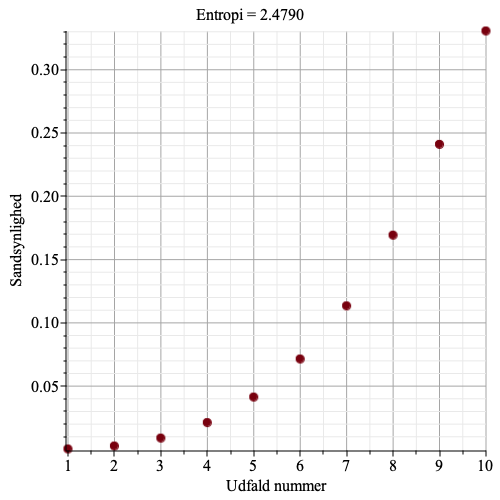
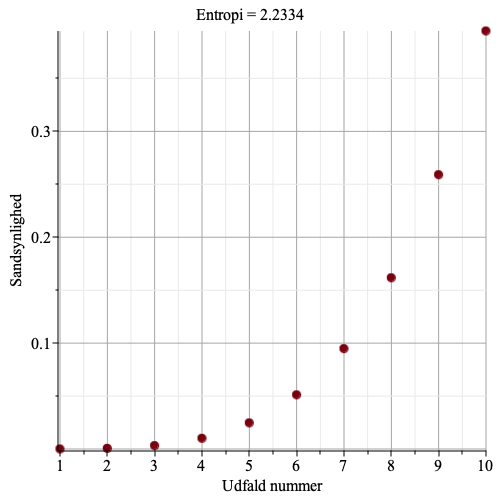
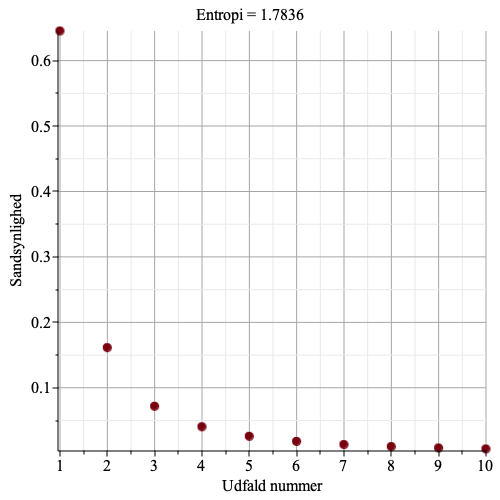
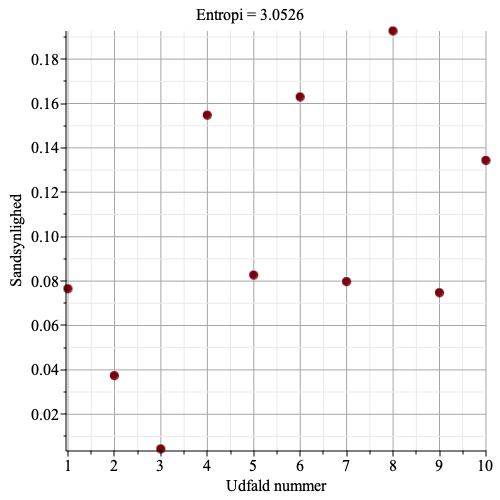
Figurerne herunder viser et punktplot over sandsynligheder for 10 udfald, og en beregnet ideel entropi. Bemærk, at jo større variation der er i sandsynlighederne, jo mindre en entropien. Det skyldes, at når der er udfald med stor sandsynlighed, så skal de, i en optimal spørgestrategi, spørges til først, og mindst sandsynlige udfald skal der spørges til sidst – på den måde skal der stille færrest mulige spørgsmål, og entropien bliver lille.
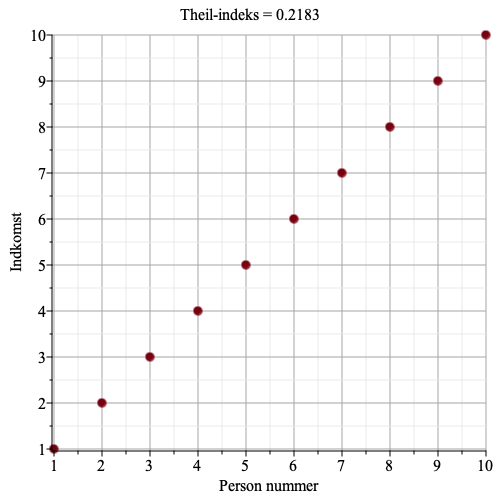
Ved at indsætte indkomsterne \[x_i\] og gennemsnittet \[\mu\] af indkomsterne, så udregnes Theil-indekset til 0.21829. Her har jeg brugt to-tals-logaritmen \[\log_2(x)\]. Det er sådan set lige meget hvilken logaritme man bruger, bare man hele tiden bruger den samme, ellers kan man jo ikke sammenligne resultaterne.
Hvis man skal bestemme Theil-indekset for grupper af personer, f.eks. hvis man skal sammenligne indkomster i forskellige lande, så er det bedst at tilpasse formlen for Theil-indekset. Som den er nu, sammenligner den individer, ikke grupper. Forskellen på individer og grupper er, at grupper varierer i størrelser, det skal der tages hensyn til ved beregning af Theil-indekset.
Formlen for Theil-indekset kommer tydeligvis fra formlen for ideel entropi. Der er dog en omvendt sammenhæng; ens sandsynligheder i formlen for ideel entropi giver stor ideel entropi. Ens indkomster i formlen for Theil-indeks giver et lille Theil-indeks.
Vi skal nu, ud fra formlen for ideel entropi, udlede formlen for Theil-indeks. Formlen for ideel entropi er givet ved
\[H=- \sum_{i=1}^{n} p_i \cdot \log_2(p_i)\]
Jeg vil nu prøve at udlede formlen for Theil-indekset fra formlen for ideel entropi.
Theil-indekset skal være tæt på nul når der er stor lighed. Men stor lighed giver stor ideel entropi. Vi beregner derfor Theil-indekset som forskellen mellem den maksimale ideelle entropi for n data og den ideelle entropi for de n data. Forskellen er dermed tæt på nul ved stor ulighed.
Vi vil nu beregne den maksimale ideelle entropi for n data.
Hvis alle udfald har samme sandsynlighed, så er den ideelle entropi størst. Antag at alle sandsynligheder er ens, dvs. \[p_i=p\] for alle i. Da er
Da de n led i summen alle er lige store, og lig \[p \cdot \log_2(p)\], så får vi videre
\[
H =- \sum_{i=1}^{n} p \cdot \log_2(p)
= -n \cdot p \cdot \log_2(p)
\]
De n sandsynligheder lagt sammen må give 1, dermed er \[p=\frac{1}{n}\].
Da \[n \cdot \frac{1}{n} = 1\] og da \[\log_2(1/n) = -\log_2(n)\], så få vi
\[
H = -n \cdot p \cdot \log_2(p)
= -n \cdot \frac{1}{n} \cdot \log_2(1/n)
= -(-\log_2(n))
= \log_2(n)
\]
Den største ideelle entropi får man altså når alle sandsynligheder er ens, og den maksimale ideelle entropi er i så fald lig \[\log_2(n)\].
Nu er vi klar til beregning af Theil-indekset.
Antag at vi har n personer med indkomsterne \[x_i\]. De n personer samler deres indkomster i en kasse, vekslet om til enkroner. Den person som tjener mest, lægger altså flere enkroner i kassen end en person som ikke tjener så meget. Vi tager så en tilfældig enkrone fra kassen. Vi vil finde ud af hvilken af de n personer som var ejer af den enkrone vi har fået fat i. Vi må kun spørge ja/nej spørgsmål, f.eks. ‘Er mønten ejet af person nummer 1?’
Da gennemsnittet \[\mu\] af indkomsterne beregnes ved brug af formlen
\[\mu = \frac{1}{n} \cdot (x_1+x_2+...+x_n)\]
så må \[\mu \cdot n\] være lig summen \[x_1+x_2+…+x_n\] af indkomsternene.
Sandsynligheden for at mønten kommer fra person i er dermed
\[p_i = \frac{x_i}{n \cdot \mu}\]
Vi tager så formlen for den ideelle entropi, og indsætter sandsynlighgederne \[p_i\] givet ved udtrykket herover. Husk at Theil-indekset beregnes som forskellen mellem den maksimale entropi \[H_{max}\] for n muligheder og den beregnede entropi for de n indkomster.
Hele sidste del kan altså reduceres til \[\log_2(n)\]. Dermed får vi
\[
T = \log_2(n)+ \frac{1}{n} \sum_{i=1}^{n} \frac{x_i}{\mu} \cdot \log_2(\frac{x_i}{\mu})-\log_2(n)
\]
Nu går \[\log_2(n)\] ud, så vi ender med resultatet
\[
T = \frac{1}{n} \sum_{i=1}^{n} \frac{x_i}{\mu} \cdot \log_2(\frac{x_i}{\mu})
\]
Hermed har vi ‘udledt’ formlen for Theil-indekset.
Vores fortolkning er, at Theil-indekset er antal ja/nej spørgsmål man skal stille, for at finde ud af hvem der ejer en given krone, målt i forhold til det maksimale antal ja/nej spørgsmål man kan komme ud for at skulle stille i det tilfælde hvor der er total lighed.
Er der total lighed, så skal man stille det maksimale antal ja/nej spørgsmål, den ideelle entropi bliver maksimal, og Theil-indekset bliver lig nul.
Ved stor ulighed, så skal man stille færre spørgsmål end det maksimale antal, og dermed bliver Theil-indekset større.
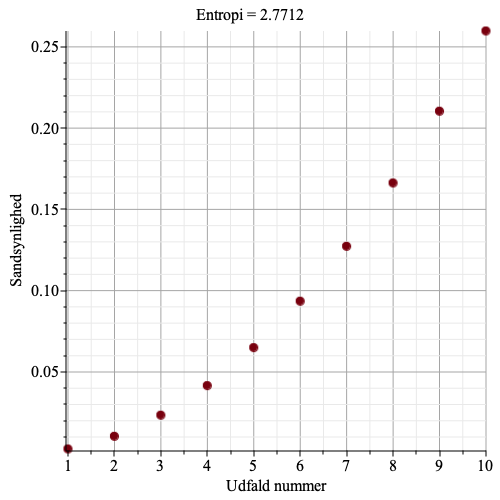
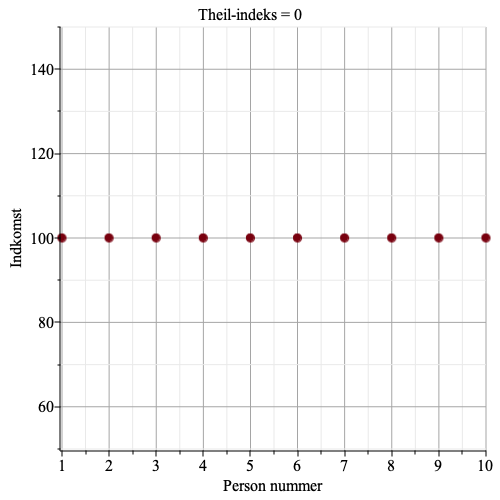
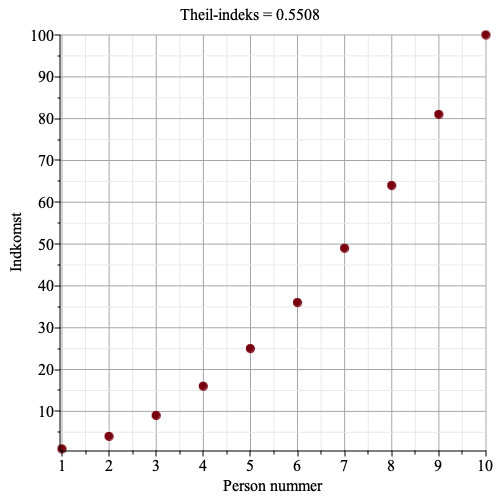
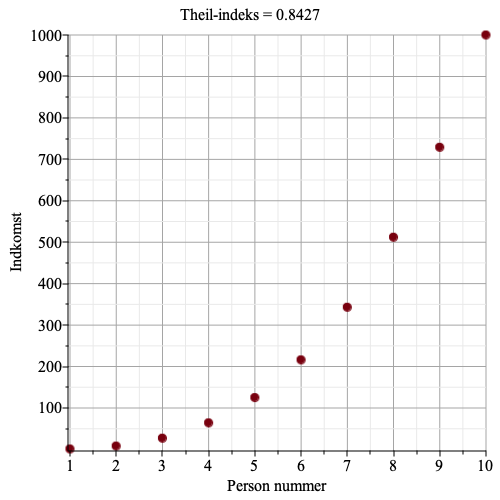
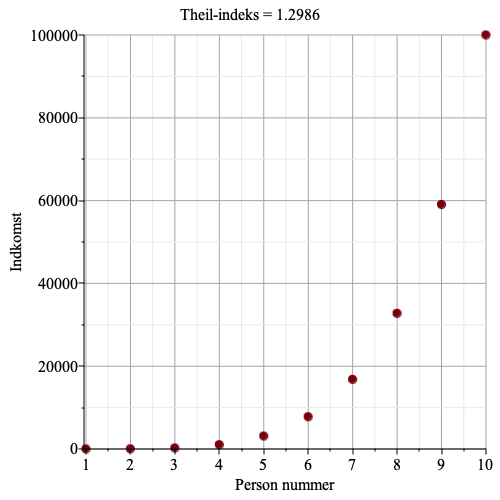
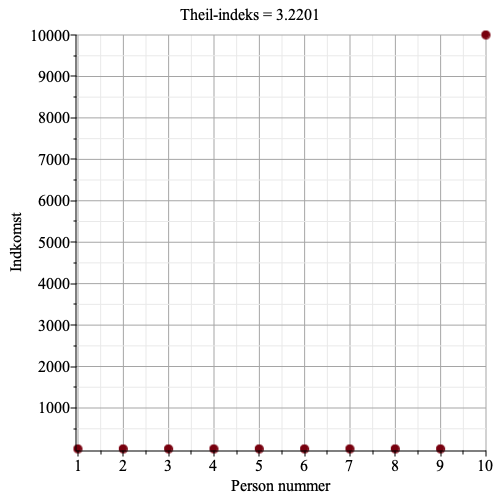
Graferne herunder viser indkomst for hver person, samt Theil-indekset.
Vi ser, at jo større ulighed, jo større bliver Theil-indekset.
I den sidste figur har person nummer 10 en indkomst på 10000 kr, de andre 9 personer har en indkomst på 100 kr. Nu bliver Theil-indekser 3.22. Den maksimale ideelle entropi bliver tæt på nul, det er jo rimelig klart hvem der ejer den krone man vælger. Da den maksimale ideelle entropi, ved lige indkomst er \[\log_2(10)=3.3219\], så bliver Theil-indekset lige under 3.3219.
Hvis alle indkomster er ens, så bliver den ideelle entropi lig \[\log_2(10)=3.3219\].
Vi så før, at den reelle entropi \[H_0\] var det spørgsmål man i gennemsnit skal stille, for at få klarhed, når man spørger efter den optimale spørgstrategi.
Antag nu at vi trækker et kort fra et kortspil med 52 kort.
Først er vi interesseret i om kuløren er sort, dvs. om kuløren er spar eller klør. Det er klart at det kræver præcis ét ja/nej spørgsmål, så den reelle entropi er 1.
Antag nu at vi er interesseret i, om det er spar es. Vi kan spørge ‘er det spar es?’. Det er et ja/nej spørgsmål. Når vi har fået svar på det spørgsmål, så ved vi om det udtrukne kort var spar es. Igen kræves netop ét ja-nej spørgsmål, så den relle entropi er 1.
Men i hvilken af de to situationer vindes der mest viden? I føste tilfælde er der 50% chance for farven sort. I tilfælde 2 er der 1/52 chance, dvs. lidt under 2%, for at det er spar es.
Hvis man i første situation for at vide at kuløren er sort, så bliver man næppe overrasket, for det er et meget sandsynligt udfald. Hvis man i andet situation får at vide at det udtrukne kort er spar es, så bliver man nok noget overrasket.
Pointen er, at man ikke får ret meget ekstra viden når man får at vide at kortet ikke er spar es, men men får mere viden når man får at vide at kortets kulør er sort.
Den reelle entropi kan altså godt være ens i to forskellige situationer, der nok ikke umiddelbart kan sammenlignes.
Lad os nu se på plat eller krone med en uærlig mønt. Vi er interesseret i om det blev ‘krone’. Lad os antage at sandsynligheden for at få krone er 3/4 = 75%, og sandsynligheden for at få plat er 1/4 = 25%.
Der skal naturligvis bruges ét spørgsmål til at få svar på spørgsmålet; ‘blev det krone?’. Hvis vi gentager forsøget igen, så skal vi igen bruge et spørgsmål for at få svar på om andet kast gav ‘krone’. Gentages forsøget 10 gange, og skal vi hver gang finde ud af om det blev ‘krone’, så skal vi bruge 10 spørgsmål.
Men hvad nu hvis vi ikke spørger efter hver kast, hvad nu hvis vi, efter f.eks. to kast, spørger til det samlede resultat?
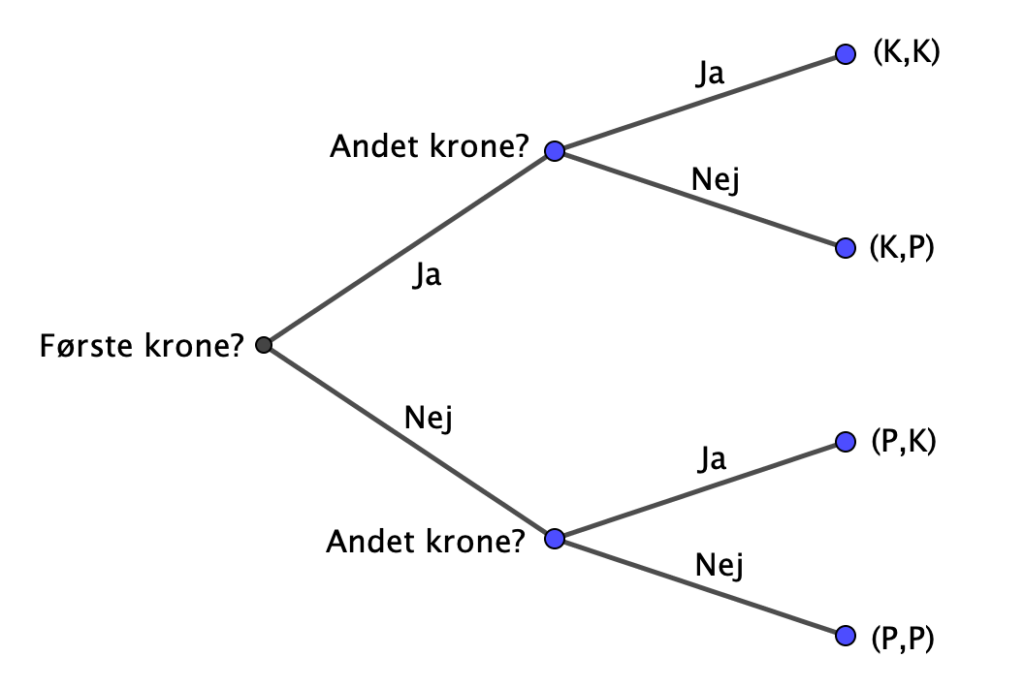
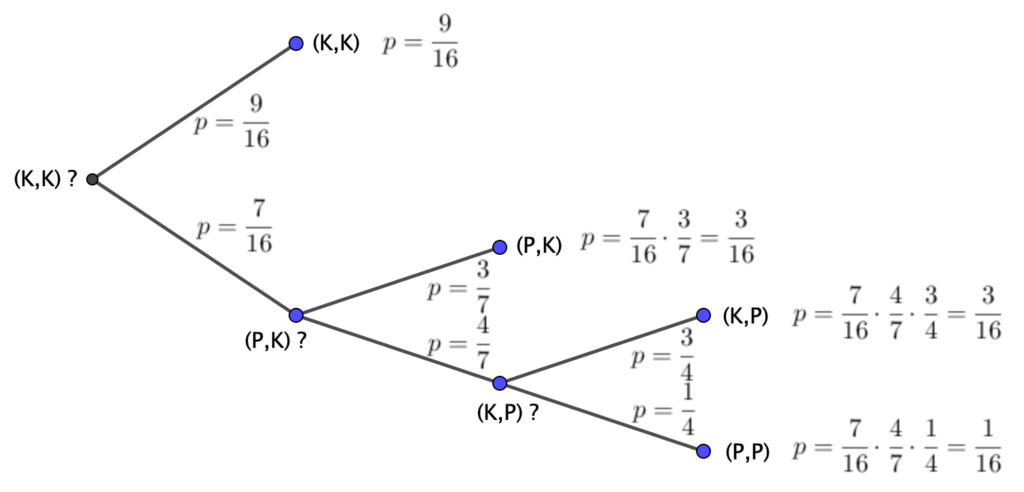
Hvis udfaldene skriver f.eks. (P,K) for første kast plat og andet kast krone, så er her de mulige udfald og de tilhørende sandsynligheder:
Spørgestrategi 1 : Vi kan spørge om første kast gav ‘krone’ Hvis ‘ja’, så gav første kast naturligvis ‘krone’, hvis ‘nej’, så gav første kast ‘plat. Nu kan vi spørge om andet kast gav ‘krone’. Det kræver, uanset sandsynlighederne, altid to spørgsmål:
Det er ikke den bedste spørgestrategi, for vi har ikke taget hensyn til at sandsynligheden for ‘krone’ er større end sandsynligheden for ‘plat’.
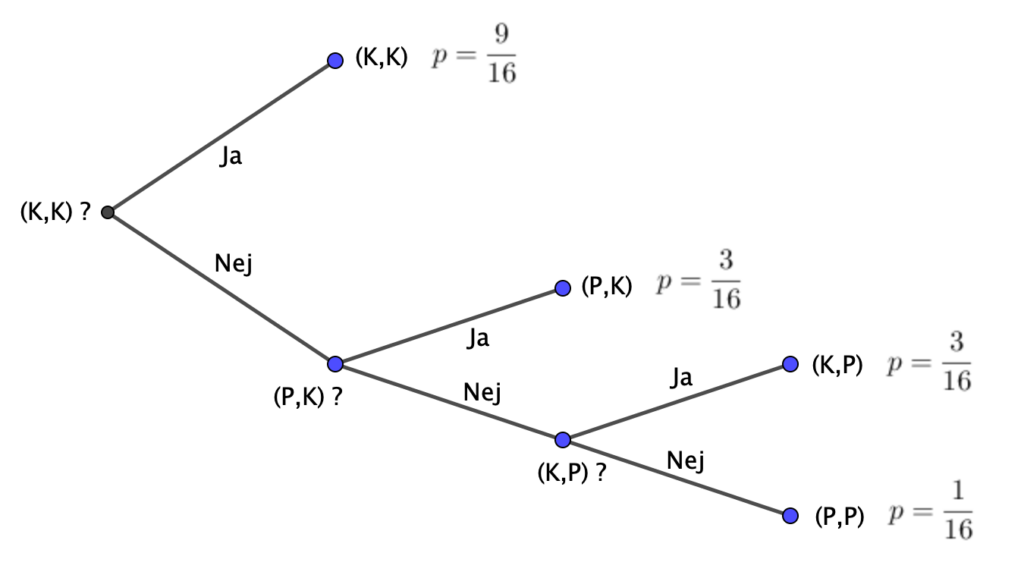
Spørgestrategi 2 : Vi spørger først om udfaldet (K,K). Hvis ‘ja’ bruger vi et spørgsmål, hvis ‘nej’ spørger vi om (P,K). Hvis ‘ja’ har vi brugt to spørgsmål, hvis ‘nej’ spørger vi om (K,P). Nu kender vi svaret.
Sandsynlighederne i træet herover kunne også beregnes ved at gange sandsynlighederne fra roden og ud til grenene, det er dog en del mere besværligt, men det virker naturligvis:
Vi ser altså, at vi, ved at udføre forsøget to gange, og så spørge til sidst, kan spørge på en mere fornuftig måde, og ende med at skulle bruge et færre antal spørgsmål, end ved bare at spørge til hvert forsøg for sig.
Ved de to gentagelser skal vi bruge 0.84 spørgsmål pr. forsøg, med spørgestrategi 2.
Hvis vi gentager forsøget endnu en gang, og efterfølgende spørger fornuftigt, så har vi naturligvis brug for flere spørgsmål, men antal spørgsmål pr. forøg bliver nok lidt mindre end de 0.84 spørgsmål pr. forsøg.
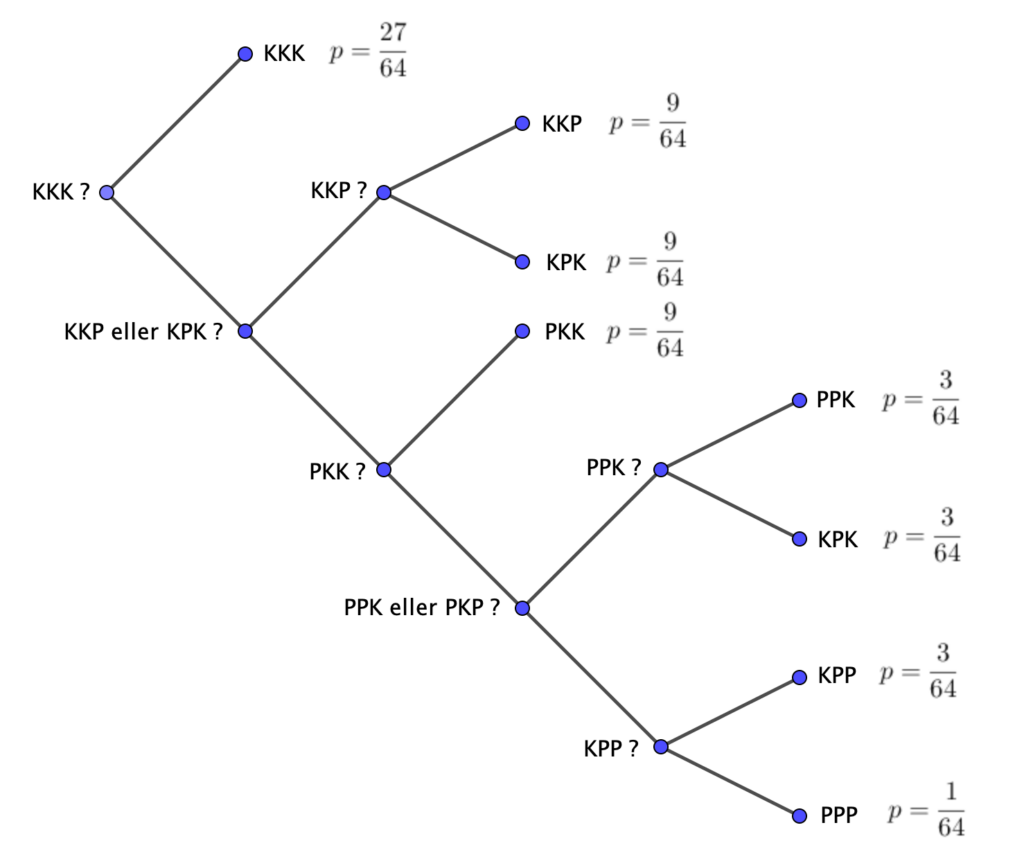
Lad os gentage forsøget tre gange. Der er i princippet fire typer udfald, med sandsynligheder:
Antal spørgsmål, pr. forsøg, er nu 0.8229. Bemærk dog, at vi ikke ved om vores spørgestrategi er optimal.
Som vi skal se i det efterfølgende, så vil antallet af spørgsmål, pr. forsøg, nærme sig mod en ‘nedre værdi’ jo flere forsøg vi udfører inden vi spørger.
Nu skal vi se på den ideelle entropi \[H\]. Lad \[F\] være et forsøg, f.eks. et møntkast. Lad \[F^k\] betegne det forsøg, der består i, at forsøget \[F\] gentages k gange. Vi definere nu
Den ideelle entropi \[H\] er altså den reelle entropi for forsøget \[F^k\], divideret med k, når antallet k af forsøg går mod uendelig.
Sagt på en anden måde; den ideelle entropi er det gennemsnitlige antal spørgsmål man skal stille, pr. forsøg, når man spørger optimalt, når antallet af forsøg går mod uendelig.
Så kan man spørge hvad man skal bruge det til, for det kan man jo ikke bare regne ud. Forsøget herover med tre møntkast med den uærlige mønt var kompliceret nok i sig, selv, hvordan ser det så ikke ud for k = 10 eller k = 1000?
I næste afsnit præsenteres formlen der på en overraskende simpel måde beregner den ideelle entropi.