
Vi vil nu udlede en formel for Theil-indekset for grupper.
Vi betynder med Theil-indekset for ‘individer’:
\[
T = \frac{1}{n} \sum_{i=1}^{n} \frac{x_i}{\mu} \cdot \log_2(\frac{x_i}{\mu})
\]
Vi har N personer, men nu er de samlet i m grupper.
Alle individer i samme gruppe har samme indkomst \[x_j\].
Antallet af personer i gruppe j kalder vi \[n_j\].
Vi bruger bogstavet j som fodtegn for at tydeliggøre hvilken gruppe vi ser på.
Gruppe 1. j = 1. Indkomst for hvert individ i gruppe 1 er \[x_1\]. Gruppe 2. j = 2. Indkomst for hvert individ i gruppe 2 er \[x_2\]. ... Gruppe m. j = m. Indkomst for hvert individ i gruppe m er \[x_m\].
Den gennemsnitlige indkomst for alle de N personer kalder vi \[\mu\].
Summen i formlen for Theil-indekset er en sum over alle personernes indkomst. Vi kan opdele summen så vi først summerer over alle personer i gruppe 1, så summerer over alle personer i gruppe 2, o.s.v. Dermed får vi:
\[
T = \frac{1}{N} \sum_{j=1}^m
\sum_{i=1}^{n_j} \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
\]
I den inderste sum \[\sum_{i=1}^{n_j} \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})\] summerer vi over alle individer i samme gruppe, og deres personlige indkomst er ens. Vi får derfor \[n_j\] led der er ens, og den inderste sum giver så
\[
\sum_{i=1}^{n_j} \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
= n_j \cdot \frac{x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
= \frac{n_j \cdot x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
\]
Vi ender med at få
\[
T = \frac{1}{N} \sum_{j=1}^m \frac{n_j \cdot x_j}{\mu} \cdot \log_2(\frac{x_j}{\mu})
= \sum_{j=1}^m \frac{n_j \cdot x_j}{N \cdot \mu } \cdot \log_2(\frac{x_j}{\mu})
\]
Dermed har vi udledt formlen for Theil-indekset for grupper:
\[
T = \sum_{j=1}^m \frac{n_j \cdot x_j}{N \cdot \mu } \cdot \log_2(\frac{x_j}{\mu})
\]
Når vi skal sammenligne indkomsterne mellem grupperne, så beregner vi Theil-indekset ved brug af formlen herover. I formlen er \[n_j\] antallet af personer i gruppe j, \[x_j\] er den individuelle indkomst i grupper j, \[\mu\] er den gennemsnitlige indkomst for alle personer, og n er antallet af personer i alt i alle grupper.
Bemærk at \[n_j \cdot x_j\] er den totale indkomst i gruppe j, og \[N \cdot \mu\] er den totale indkomst i befolkningen.
Man kan diskutere det fornuftige i at antage at alle personer i samme gruppe har samme indkomst. Det kan jo være at man har udvalgt sine grupper udfra indkomst-nivaeu, og så er det naturligvis en fornuftig antalelse. Andre gange er det ikke en fornuftig antagelse, og man kan så undersøge/overveje hvilken betydning det så får. Se også ‘dekomposition af Theil-indekset’ hvor man både sammeligner individer og grupper, og finder ud af hvor meget variation i individuelle indkomster betyder for det samlede Theil-indeks, og hvor meget gruppe-variation i indkomster betyder for det samlede Theil-index.
Lad os som eksempel se på data fra nogle amerikanske stater:
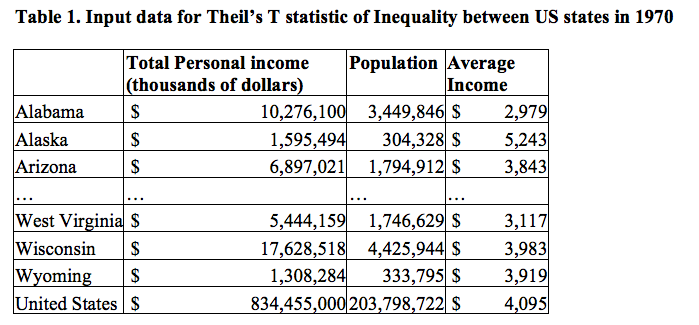
Vi vil beregne Alabamas bidrag til Theil-indekset:
\[T_{Alabama} = \frac{3449846}{203798722} \cdot \frac{2978}{4095} \cdot \log_2(\frac{2979}{4095})
= -0.0057\]
Alabamas bidrag til Theil-indekset bliver negativt da gennemsnitsindkomsten i Alabama ligger under gennemsnitsindkomsten i USA. Alaskas bidrag til Theil-indekset beregnes på samme måde, og man får 0.00068.
For at beregne Theil-indekset for USA skal vi beregne hver af staternes bidrag til Theil-indekset, og så addere dem.